近期我会读大量的文献,将这些文献的收获po在博客上,第一篇论文是关于目标检测,附上原文地址:https://arxiv.org/abs/1712.00726
Contribution
文章主要解决的问题是如何确定用于区分positive、negative proposal的IoU阈值,作者提出了通过级联多个不同IoU阈值的detector,达到好的detection performance。
IoU
首先要说明什么是IoU阈值,detector画出的bounding box中可能含有30%、50%、70%的被检测物体,我们需要设置一个阈值,从而能够高效的分离正负样例。
然而阈值设置的过大或过小会带来诸多问题,阈值过小时,会导致detector对于positive proposal的识别能力降低,并且引入大量负样例,导致模型训练时间增长;但阈值设置太大,同样会导致一些问题:
-
1) overfitting during training, 正例样本会大量减少;
-
2) IoU mismatch, 不同的IoU阈值适用于不同的样本集。
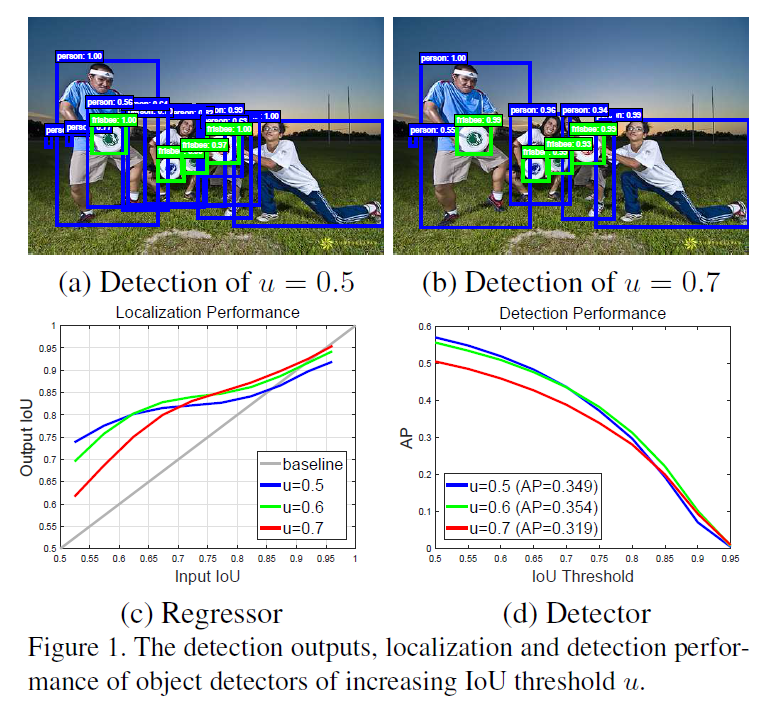
作者通过实验证明了不同的IoU阈值需要根据positive proposal中的IoU来确定,过大或者过小都会导致一些问题,那么如何确定一个普适的,generalized model?ensemble,或者更好一些,cascade不同IoU 阈值的models,逐步的提升detector的效果。
Object Detection
在这之前,我并没有系统的梳理过 object detection 的模型、方法,本篇文章中则很好的对现有几种方法进行了整理。 首先,所有模型可以分为
-1) one-stage framework, 典型代表即为YOLO(You Only Look Once),RetinaNet;
-2) two-stage framework, 典型代表为R-CNN, fast R-CNN, faster R-CNN;
-3) multi-stage framewwork
当然,YOLO的速度比较快,计算消耗低,但是效果相对较差,而R-CNN派别中则存在识别速度叫慢的问题,本文中的改进是以R-CNN为基础的。R-CNN在训练过程中主要是分为两个stages,一个是识别并归类的classifier,一个是精确localization的regressor,即给出位置的四个返回值(x, y, w, h)。
Why it works?
至于为什么性能提升,作者这样解释:
-
1) 不存在overfitting的问题,proposal在被一级一级的训练过程中,positive proposals的数量不会下降太多,因为每一级设定的阈值总是不会太严苛;
-
2) 随着一级一级IoU的增大,模型能够达到很好的效果。
Reference
-
1) Zhaowei Cai, Nuno Vasconcelos, Cascade R-CNN: Delving into High Quality Object Detection
-
2) https://towardsdatascience.com/r-cnn-fast-r-cnn-faster-r-cnn-yolo-object-detection-algorithms-36d53571365e