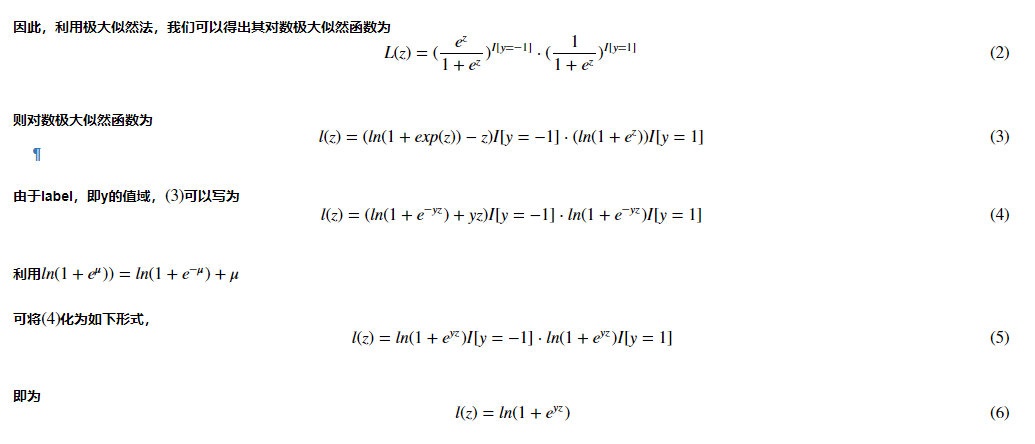Q
问题来源于CS229(2017Autumn)课程中,ps2的第一题,题目中给出了两组二分类的数据和一个LR的模型,关于题目中的具体问题不再详述,倒是题目中给出的模型让我花
了很长时间才搞明白,现在po出来。题目中数据http://cs229.stanford.edu/ps/ps2/ data_a.txt,模型 http://cs229.stanford.edu/ ps/ps2/lr_debug.py,
模型中的部分代码让我困惑,
def calc_grad(X, Y, theta):
m, n = X.shape
grad = np.zeros(theta.shape)
margins = Y * X.dot(theta)
probs = 1. / (1 + np.exp(margins))
grad = -(1./m) * (X.T.dot(probs * Y))
这是题目中用于模型求导的代码,这与我之前接触到的标签为0,1的LR模型不同,下面给出标签为-1,1时,LR目标函数和梯度的求解过程。
推导过程